ClusteringRandomForest¶

Signals¶
- Inputs:
- Data
Data to be used for learning.
- Outputs:
- Learner or Classifier
Description¶
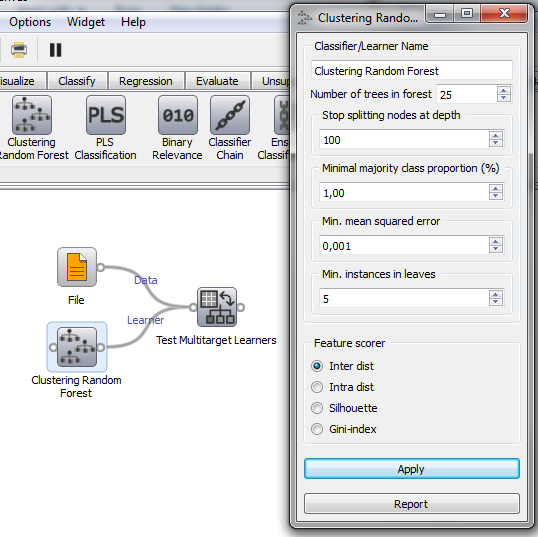
A clustering random forest is a random forest consisting of clustering trees. The usage is straightforward and the setting are described below.
Settings¶
Number of trees in forest
Number of trees in forest.
Stop splitting nodes at depth
Maximal depth of tree.
Minimal majority class proportion
Minimal proportion of the majority class value each of the class variables has to reach to stop induction (only used for classification).
Min mean squared error
Minimal mean squared error each of the class variables has to reach to stop induction (only used for regression).
Min. instances in leaves
Minimal number of instances in leaves. Instance count is weighed.
Feature scorer
- Inter dist (default) - Euclidean distance between centroids of clusters
- Intra dist - average Euclidean distance of each member of a cluster to the centroid of that cluster
- Silhouette - silhouette (http://en.wikipedia.org/wiki/Silhouette_(clustering)) measure calculated with euclidean distances between clusters instead of elements of a cluster.
- Gini-index - calculates the Gini-gain index, should be used with class variables with nominal values